As the title states, the requirement is simple – Extract max date from multiple excel files with varying schemas. I had a task where the requirement was to go through about 30 odd excel files and pick max date from each of them for monitoring purpose. All the files do not have necessarily have same schemas i.e. same number of columns or sheet name for that matter.
Just looking at the requirement, I knew this is a cakewalk for Alteryx. You see once you get a small taste of how a macro works, you will begin to realize the incredible power of the ability to customize every single component of the workflow – input tool, output tool, filter, join. Anything, you just name it, it will do it for you. It will put those tiny black thingy on the controls and hallelujah! you are set.

I did some simple mind calc and bam, I knew I could rig this up effortlessly.
Without any further ado, let’s get into this with an example. Like every other person out there I consume a lot, I mean a LOT of audio/movie content be it movies, series or podcasts. So I have three files now to keep track of these –
1. Movies Seen.xlsx containing the following data-
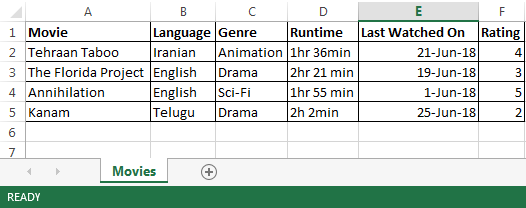
2. Series Seen.xlsx containing the following data –

3.Podcasts Heard.xlsx containing the following data –

As can be seen all the files above are having different column names and different sheet names too. My goal is to get when was the last movie that I saw or series I saw or podcast I heard.
Here is the expected result –
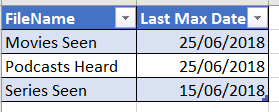
Solution –
My first step was to create a lookup file – media_config_data.csv which looks like below –

We will make use of this later. First let’s create one simple workflow that gives the max date from one of the files above i.e. Movies Seen.xlsx. Here is the screenshot of the base workflow –

The workflow does following things –
1. Use ‘Input Data’ and connect to the excel file.
2. Add a ‘Formula Tool’ and create new column ‘Max Date’ and set it to ‘Last Watched On’
3. Add a ‘Select’ transform and deselect all the columns excepting the ‘Max Date’ and ‘File Name’ column
4. Add a ‘Summarize’ transform and set it as ‘Last Max Date’
5. Generates a dummy output
Ensure that the workflow works without any error. The next step is to create a ‘macro’ out of it. Some of ‘comments’ in the above screen shot should give an idea of what is going to happen.
Step 1 – Macro to obtain Max of Date column
Perform the following steps to create the macro. This is where the actual magic happens –
1. Drag in three ‘Control Paramters’ on to the canvas and set the labels as –
Excel Name, Sheet Name, Date Column Name.
2. Connect the ‘Excel Name’ control parameter’s magnifying glass to lightning strike of ‘Input Tool’. An ‘Update value’ action tool will popup.
3. Perform the following actions on selecting the ‘Update value’ tool as shown below –

4. Perform the steps (2) and (3) for Sheet Name control parameter and in following through ‘Replace a specific string:’ Movies.
5. Now connect the ‘Date Column Name’ control parameter to the lightning strike of ‘Formula’ tool and perform the actions as seen below –

6. Lastly remove the ‘Output’ tool and connect ‘Macro output’.
7. Save the file as ‘Obtain Max Date from Excel File’.
Here is how the macro would like like once done –

Step 2 – Workflow to process the files
This workflow is where we use Directory tool, to obtain all the excel files and get file name and full file path, join it up with config file and obtain the three variables that the above macro needs –
1. Excel Name
2. Sheet Name
3. Date Column Name
Here is how the workflow would look like –

On running the workflow, we get the desired output as shown below –








































