As I keep progressing on my journey with Alteryx, I can’t help keep thinking on exploring all the various ways with which this can be stretched and explored. Here are some of the ETL scenarios that I have in mind –
- Incremental data loads
- Loading files from folder for a certain date range and moving them to archive
- Error handling and logging
- Performance handling (loading ~1M records)
- Configurability and deployment across various environments
- Version control
These are what I can think of now. Let me start off this post with the first of the above scenarios i.e. incremental data loads. This is a quite common ETL scenarios that every developer gets to work on over course of his career.
Here is a sample staging table from along with sample data in it. This would become the source table –
create table stg_orders( id int, description varchar(10), amount decimal(6,2), created_date date ); insert into stg_orders values (1,'Apples',20,'2017-12-15'); insert into stg_orders values (2,'Bananas',10,'2017-12-15'); insert into stg_orders values (3,'Mangoes',25,'2017-12-15');
Here is the destination table to which data is being loaded.
create table orders( id int, description varchar(10), amount decimal(6,2), created_date date );
Incremental loading refers to the process of loading only changed data from source to destination. Identification of this ‘changed’ data would vary based on the business requirements. Most often it is chosen based on the datetime field, which is the case here.
First thing to ensure is to have a controller table at the destination that will hold the last loaded datetime. Below is the controller table that I am using for this demo –
create table controller( last_refreshed_date date );
With basic structure in place, let’s begin to assemble the workflow. Here is how the final output would look like –
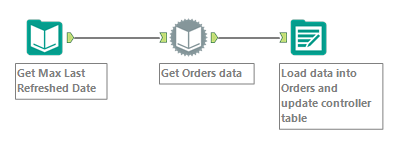
It’s THAT simple. Just three little transforms. That’s the beauty of Alteryx. All the nitty-gritty itsy bitsy column details are all completely hidden. Let’s look at each one of them. The first controller is a ‘Input Tool’ that gets the max last refreshed date value from the existing data. Here is the query used for it. When the workflow is first run, the controller would not be having any data in it, hence I have put an arbitary date of 12th December, 2017. Ideally this value would be current date.-
select coalesce(max(last_refreshed_date),'2017-12-12') as last_refreshed_date from controller;
The second tool is a Dynamic Input tool – ‘Get Orders data’ wherein the filter gets added on and requires bit more explanation. Once you drag and drop Dynamic Input tool, here are the steps that are to be taken as shown below.

Click on ‘Edit’ button. In the ‘Connect to a File or Database’ click to obtain the source query and then in the SQL Editor, put the actual source query that fetches the data from the data from the source. As can be seen the date that I specified is an arbitary date. Once you put in the query click on ‘Ok’ in the current and subsequent window to close the wizard. Connect this to the previous transform i.e. the ‘Get Max Last Refreshed Date’ Input tool.
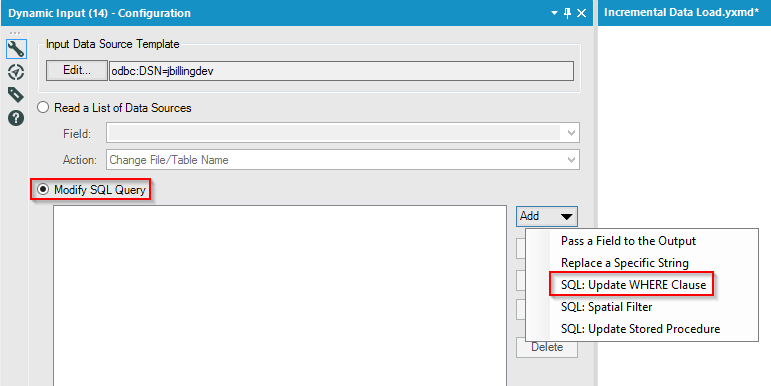
At this point you are just connected to the source SQL query and we now need to configure it so that filter is udpated. Now select ‘Modify SQL Query’ and click on ‘Add’ dropdown and choose ‘SQL: Update WHERE Clause’. This will pop-up a new window
This is where you can say ‘magic’ happens. As you see above, the first part is where you need to select the appropriate part of the where clause. If you have multiple clauses in your WHERE clause, all of these appear in the drop-down. The wizard automatically reads in the filter and identifies the field that needs to be replaced. The second part is where you define the field with which you will be replacing, which in our case is the ‘last_refreshed_date’ and then click on ‘OK’.

Let’s get to the last part i.e. ‘Output Data’ tool – Load data into Orders and update controller table. This control has among many options – ‘Post Create SQL Statement’ which is what we are going to use. Here is the sql statement that I have put in it for –
BEGIN TRANSACTION; INSERT INTO controller( last_refreshed_date ) SELECT MAX(created_date) FROM orders; END TRANSACTION;
This is a feature that even informatica has but only as part of the source. Here in Alteryx, both ‘Input Data’ and ‘Output Data’ has this option. Here is how the output properties would look like –

With all set let’s run the workflow. Here is the data from the orders table post-run –

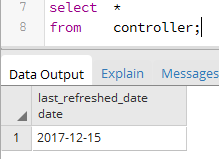
Here is the data in ‘Controller’ table –
Let’s insert some more data in the source table –
insert into stg_orders values (4,'Apples',30,'2017-12-16'); insert into stg_orders values (5,'Bananas',2,'2017-12-17');
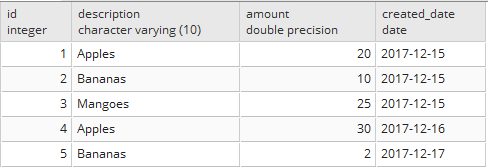
In this run, you can see that only 2 records get picked which is what is expected and here is the data from the orders table –
That’s about it. Here are few points that I would like to point out –
1. In a typical ETL, the controller table would have few more columns such as Id, Total Records etc. basically a auditing table.
2. The source SQL Query may not be as simple as the one that is pasted in this demo but a complex one especially when loading data from a Operational Data Store (ODS) to a Data Warehouse (DW).
3. At no point of team we needed any variable to perform all these operations.

any chance this works with Oracle 12c? as i can’t get it to work without error messages
Could you let me know what kind of error messages you are getting? This approach should work with any database.
[…] blog can be seen as a follow on from Karthik V’s blog at https://karthikvankadara.com/2017/12/20/incremental-data-load-using-alteryx/ in which he clearly explains how to use the Dynamic Input tool for incremental data […]
Can the same approach work with Calgary database ?
Hey Snehal, Yes, it should. Thing to remember is the process you are using to connect to the source is via SQL Queries. If you are able to do that with the Calgary database, then I don’t see why it won’t work.