Quite often I see that in many projects that I worked with, there are some disparate data pipelines doing the same tasks but with different operators, different methodology in achieving the same objective. This could be due to different people joining the project not being aware of similar work done before or people trying to come with their own approach. It’s not an ideal way of working and where possible it would be good to have a framework set and have the team implement it with end to end documentation to guide them.
In course of my work, I came across a solution wherein they had implemented a robust solution to achieve this albeit with extra layering i.e. nesting at two levels down which I will explain further. At first, it was very hard for me to absorb what was going on. Now, with some time in my hands and being able to relook at it from fresh perspective I am able to decode it better and appreciate the work done. This is my attempt to make it easier for people to read and implement it for their own use case.
Business Problem
Let’s say we need to perform data loads for a data warehousing project in GCP. The typical flow for a table would be as shown below –
In the project that I had worked there were about approx. 90 tables for which data loads were being loaded on day to day basis comprising of both dimensions and fact tables using the same flow. Some of the dimensional tables were of type 2. They accomplished this by creating 6 separate DAG’s comprising by spreading out the tables (mix of heavy loads vs light loads). It was a very well built robust system by using dynamic DAG generation.
Another use case I can see where this can be implemented is data pipelines where light weight ad-hoc data loads which are driven by the business.
Solution
Airflow 2.0 onwards, there is a TaskGroup operator which caters to this use case. However, when it comes to Airflow 1.x there doesn’t seem to be a cohesive explanation of how it can be done. Even Marc Lamberti’s blog is catering to 2.0 and I haven’t been able to test or implement as our Cloud Composer is of Airflow 1.x version. The stackoverflow’s answers such as this or this look very complex and hard to follow. I am very surprised why nobody talks about the SubDAGOperator.
This is exactly what was being used and I feel the process is simple and straightforward to implement. Firstly, get the most basic DAG containing all the list of tasks to be performed for one particular table as shown below –
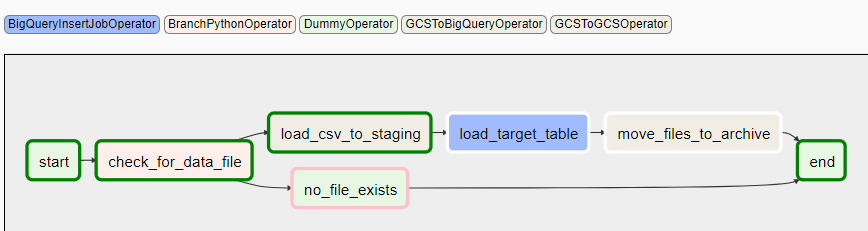
The DAG performs the ETL process described above in the diagram. Here is the break-up of the tasks present and operators used.
| # | Task Name | Operator | Description |
| 1 | start, end, no_file_exists | DummyOperator | |
| 2 | load_csv_to_staging | GCSToBigQueryOperator | Loads data from GCS to BigQuery table using schema definition to perform dat a type validation |
| 3 | load_target_table | BigQueryInsertJobOperator | Uses table.sql file to encapsulate all the business logic for moving data from staging to target. Here is where you can put in auditing, error handling, data archiving etc. |
| 4 | move_files_to_archive | GCSToGCSOperator | Moves the processed file from staging to archive. |
Ensure this basic workflow is working as expected. Next step is to understand, how to do this multiple times. For this post, I am using the data from Wikipedia containing Netflix Movies / Series releases for year 2022. Here is what I have done, I have taken the data from these two sites as two tables. I then generated some files out of it. Here is a sample file – netflix_movies_20221120.csv
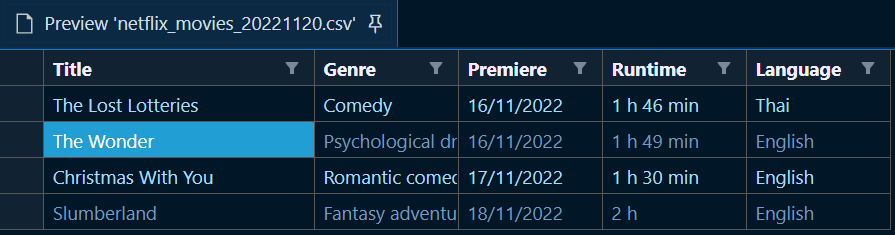
Say, we get weekly data feed from Netflix to load upcoming series / movies and our job is to process it through end to end in two tables – netflix_movies , netflix_series in our target dataset. As per the flow, I also created two staging tables netflix_movies_stg, netflix_series_stg in the staging dataset.
Here are series of steps to be done –
Create the following two variables in the Airflow
- etl_config – JSON Variable to hold all the pesky details such as PROJECT_ID, SOURCE_BUCKET, STAGING_DATASET etc. For this example here is how the value looks like –
{ “Template_Searchpath”:”/home/airflow/gcs/dags/sql/data_import” ,”Project_ID”:”gcp-project-id” ,”Staging_Dataset”:”data_import” ,”Target_Dataset”:”data_import” ,”Staging_Folder”:”staging”,”Source_Bucket”:”data_import_dev” ,”Archive_Folder”:”archive”} - data_import_tables_list – Contains the list of tables for which this needs to be dynamically generated. For this example value would be – netflix_movies, netflix_series.
Once done, here is how the DAG definition would look like –
with dag:
# Top DAG Initial Task
start = DummyOperator(task_id="start")
daily_load_tables_list = DATA_IMPORT_TABLES_LIST.split(',')
# variable to hold the DAG's created for each table.
# This gets materialized as a DAG in a nested manner.
level1_subdag_operators = []
# loop through each table
for table in daily_load_tables_list:
# uses a DAG variable to create new DAG
level1_dag = create_sub_dag(
MAIN_DAG_ID #parent dag name
,table #child dag name
,datetime(2022,11,22)
,'@once'
,TEMPLATE_SEARCHPATH
)
# materializes the newly created SubDAG
level1_subdag_operator = SubDagOperator(
subdag = level1_dag,
task_id = table,
priority_weight = 1,
weight_rule=WeightRule.ABSOLUTE,
dag = dag
)
level1_subdag_operators.append(level1_subdag_operator)
# all the tasks that are required for each table are
# generated via this task
create_tasks(level1_dag, table)
level1_dag = None
start >> level1_subdag_operatorsThere are two helper functions used in the code above – create_sub_dag and create_tasks. The code for the helper function is shown below –
# Helper methods for subdag and subtask creation
def create_sub_dag(parent_dag_name, child_dag_name, start_date, schedule_interval, template_searchpath):
''' Returns a DAG which has the dag_id formatted as parent.child '''
return DAG(
dag_id='{}.{}'.format(parent_dag_name, child_dag_name),
schedule_interval=schedule_interval,
template_searchpath=template_searchpath,
start_date=start_date,
default_args=default_args,
max_active_runs=15
)
The create_tasks function has all the operators that are needed for each table task. The full code can be found in the git link at end of this post.
Here is how the DAG would look like once set-up –
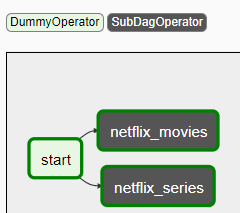
If you click on netflix_movies, a pop-up appears similar to how they appear when you click on Airflow operator with ability to Zoom into the sub-dag.
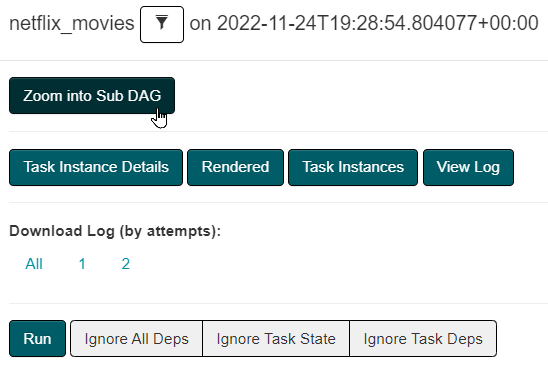
If you click on the button, you will then be represented with all the tasks for that DAG –
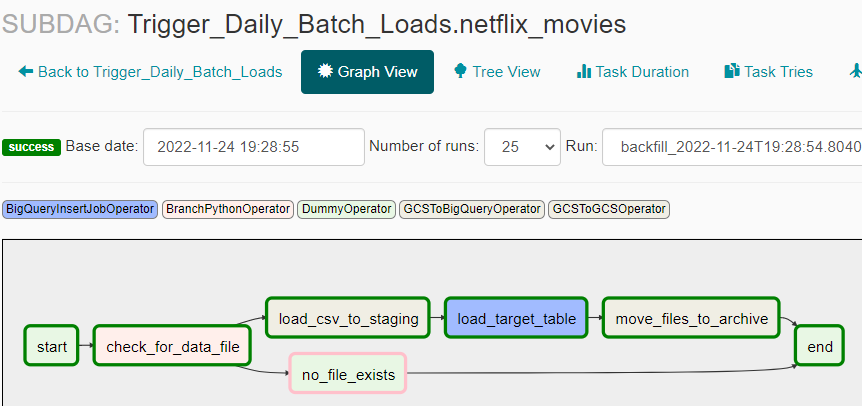
That’s about it. Simple and elegant and gets the job done.
Github link – Trigger_Daily_Batch_Loads
