I had an interesting business problem to solve and wanted to share on how this can be achieved.
Business Problem
On daily basis a zip file containing various flat files is dropped at a file location. Contents of the flat files are to be read and extracted. All the files have the same metadata.
File names within the zip file are dynamic.
Solution
Alteryx provides out of the box Input tool for working with zip files. All one needs to do is drag and drop the zip file on to the canvas and tool itself will pop-up asking which files to be extracted as shown below.

However, what steps are needed to make this process dynamic is pretty hard to find. Of course, one can rig up a Control Parameter on the top and have the zip file path updated. That’s about it though. Nothing much can be done after.
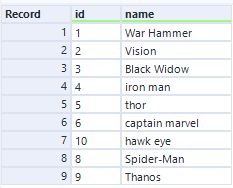
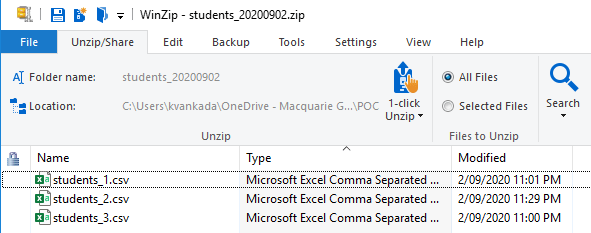
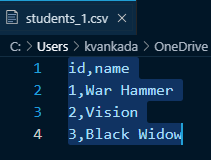
Let’s first look at the sample zip file named students_20200902.zip and the files within
My solution involves using Python entirely. Working on this, I remembered similar tweaks I used when working with SSIS. Anything that cannot be done using the existing Data Transformation Tasks (DFT), Script Task come to the rescue. Whole programming logic can be embedded within to get the task done.
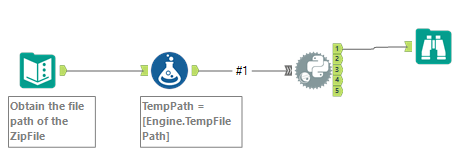
As can be seen below, this is how the end workflow would look like.
Text Input – Contains the full filepath of the zipfile
Formula Tool – Adds a TempPath variable whose value equal to engine’s TempFilePath
Python – Contains the full logic for extraction of data from the files within.
Let’s now focus on Python tool. Here is what the tool does at high level –
1. Use Zip command and unzip the files to Temp location.
2. Use Panda library’s pd.concat and pd.read_csv commands and load all the data into a dataframe, which is then sent to output.
3. Delete all the files from Temp location.
Listed below is the Python Code –
#################################
# List all non-standard packages to be imported by your
# script here (only missing packages will be installed)
from ayx import Package
#Package.installPackages(['pandas','numpy'])
#################################
from ayx import Alteryx
from csv import reader
import pandas as pd
import os
from zipfile import ZipFile
#################################
# read all the inputs
data = Alteryx.read('#1')
# we need to use .any() component as data read would be in the form
# of record set and we need to take one row out of it
zip_file_path = data['Path'].any()
temp_file_path = data['TempPath'].any()
#declare variables
extensions = ['.csv']
#################################
# Create a ZipFile Object and load *.zip in it
with ZipFile(zip_file_path, 'r') as zipObj:
# Extract all the contents of zip file from TempPath directory
zipObj.extractall(temp_file_path)
#################################
# variable to hold list of paths for the extracted csv files
file_list = []
#loop through all the files in the directory
for root, dirnames, filenames in os.walk(temp_file_path):
for file in filenames:
#get file extension and name
fname, fext = os.path.splitext(file)
#parse the file only if the extension is of desired extensions
if fext in extensions:
#open the file and read contents
filepath = os.path.join(root, file)
file_list.append(filepath)
# get the combined data
combined_csv = pd.concat( [ pd.read_csv(f) for f in file_list ])
# delete the files post processing
filenames = os.listdir(temp_file_path)
for filename in filenames:
if filename.endswith(".csv"):
os.remove(os.path.join(temp_file_path, filename))
#################################
Alteryx.write(combined_csv, 1)
When you drag in a Python tool, by default the Jupyter interface will open up when clicking on the ‘Configuration’ page. It will be set to ‘Interactive Mode’ as shown below –
Once code is working as expected, do remember to open this tool again and set the mode to ‘Production’. This will speed up execution and it doesn’t give any intermediary outputs that we use for debugging the code.

That’s about it. The best about this code is, it is file-agnostic i.e. it doesn’t matter if the metadata of the files within change, the solution still works.
Since read_csv has multitude of options catering to all types of needs i.e. delimiter type, header row etc., the solution can be made flexible to handle all types of files data to extract.
Here is the final output post running the job.